
こんにちは、Yuinaです🍑
今日も100本ノックの解説の続きをやっていきます!
よろしくお願いいたします!
ノック46本目:カテゴリカル変数を取り扱う
まず、カテゴリカル変数の説明をします。カテゴリカル変数とは、性別やキャンペーンの種類などカテゴリー関連のデータのことをいいます。
今回は、カテゴリカル変数の値をダミー変数化していきます。
ダミー変数化とはカテゴリカル変数(例えば、性別や地域、曜日など)を、数値的な形式に変換する方法です。
実際にノックを進めながら確認していきます。
target_col = ["campaign_name", "class_name", "gender", "count_1", "routine_flg", "period", "is_deleted"]まず、前回の投稿で作成したpredict_dataデータフレームから指定された列(target_col)だけを取り出して、新しいデータフレームを作成します。
predict_data = predict_data[target_col]こちらでは、元の predict_data データフレームから、target_col にリストされた列だけを取り出して新しいデータフレームを作成します。
こちらは現時点でのpredict_dataの状態です。↓
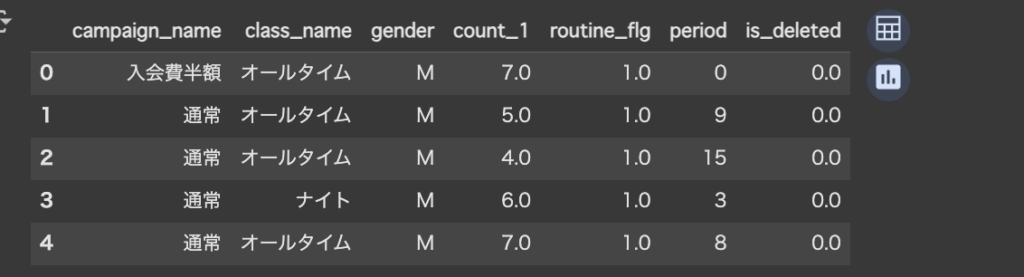
次にpandasのget_dummies 関数を使って、predict_dataというデータフレーム内のカテゴリカル変数をダミー変数化ます。
predict_data = pd.get_dummies(predict_data) predict_data.head()pd.get_dummies(predict_data) を適用すると、次のようなダミー変数化されたデータフレームが生成されます。
イメージとしてはこんな感じです。
| 入会料金_全額 | 入会料金_半額 | 入会料金_無料 | 性別_男性 | 性別_女性 |
|---|---|---|---|---|
| 1 | 0 | 0 | 1 | 0 |
| 0 | 1 | 0 | 0 | 1 |
| 0 | 0 | 1 | 1 | 0 |
今の状態を表示させてみます。

カテゴリカル変数の中身がTrue/Falseで表示されてしまっています。
元のデータがカテゴリカル変数(文字列やカテゴリ型)であれば、その列をobject型やcategory型に変換できるので、適切にダミー変数化します。
# DataFrame内のbool型(True/False)をすべて 0/1 に変換
predict_data = predict_data.astype(int)
cols_to_convert = [
'campaign_name_入会費半額',
'campaign_name_入会費無料',
'class_name_オールタイム',
'class_name_デイタイム',
'gender_F'
]
predict_data[cols_to_convert] = predict_data[cols_to_convert].astype(int)再度predict_data.head()で状態を確認してみます。

無事、適切な形でダミー変数化できました。
ノック47本目:決定木を用いて顧客の継続/退会を予測する
決定木を用いて退会予測をします。
まず、ライブラリをインポートします。
from sklearn.tree import DecisionTreeClassifier
import sklearn.model_selection1行目で決定機をしようするためのライブラリをインポートします。
2行目は学習データと評価データを分割するために必要なライブラリです。
まず、訓練データとテストデータを作っていきます。
exit = predict_data.loc[predict_data["is_deleted"]==1]
conti = predict_data.loc[predict_data["is_deleted"]==0].sample(len(exit), random_state=0)現在、データ件数が退会(1104件)と継続(2842件)となっています。
継続データをランダムに選んで1104件に抑えることで、バランスを取ったデータセットを作っています。
exitに退会データ、contiに継続データ(サンプリング後)をいれます。
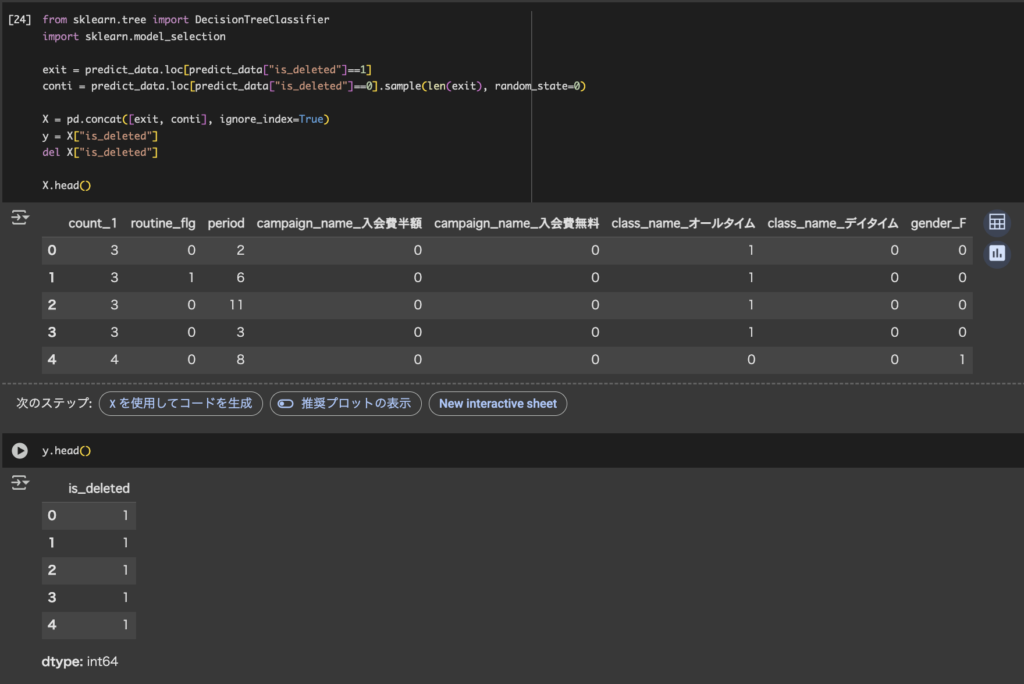
X = pd.concat([exit, conti], ignore_index=True)exitとcontiを結合してXに入れます。(説明変数:特徴量)
y = X["is_deleted"]
del X["is_deleted"]
目的変数 yにis_deletedを入れ、Xからは削除します。(目的変数:退会or継続)
ここまでのイメージ図はこちらです↓
▼ predict_data(元のデータ)
┌───────────────┐
│ いろんな特徴量 │ ← 説明変数
├───────────────┤
│ is_deleted列 │ ← 目的変数
└───────────────┘
↓ 退会者と継続者を半々にして…
▼ X(入力データ)
┌───────────────┐
│ is_deleted以外 │ ← モデルが学習するための材料
└───────────────┘
▼ y(正解ラベル)
┌─────────────┐
│ is_deleted列 │ ← モデルが目指す正解
└─────────────┘続いて、Xとyを訓練データとテストデータに分割します。
X_train, X_test, y_train, y_test = sklearn.model_selection.train_test_split(X,y, random_state=0)続いて決定木(Decision Tree)という機械学習モデルを作成します。
model = DecisionTreeClassifier(random_state=0)ここでは、木の枝みたいに「こういう条件ならこっちに進む」という分岐をいっぱい作って、 「この人は退会しそう」とか「この人は継続しそう」ってルールを学習してくれるモデルを準備しています。
model.fit(X_train, y_train)こちらは、2つ(X_train, y_train)の関係性を使って、「退会しそうなパターン」を学習させています。
イメージとしては、
データ先生:「この特徴を持ってる人は退会しました!」
モデル :「なるほど、こういう条件が重なると退会の可能性があるんだな」
っていうのをたくさんのデータで繰り返して、ルールを覚えるみたいな感じです。
y_test_pred = model.predict(X_test)X_testはまだ正解を見せていない「テスト用データ」で、
この人たちが退会しそうかどうかを学習済みのモデルに予測させます。
モデル:「ふむふむ、この特徴の人…うーん、これは退会しそう(1)かな!」
「ふむふむ、この特徴の人…うーん、これは退会しなさそうだから(0)かな!」
→ そうやって、y_test_pred に [1, 0, 1, 0, 0, …] みたいな予測結果が返ってくる!
っというイメージです。
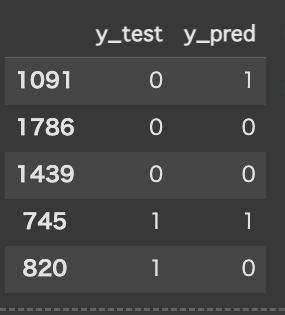
予測結果はこのようになりました。

results_test = pd.DataFrame({"y_test":y_test ,"y_pred":y_test_pred })
results_test.head()データフレームを使い、実際の結果と予測を並べて確認します。
y_test は、テストデータ(実際にどうだったか)を表す正解のラベルです。
y_pred は、モデルが予測した結果です。
表示されている5件だと、
正解は1786,1439,745で
不正解は1091,820という結果になりました。
ノック48本目:result_testデータを集計して正解率を出す
正解率は正解数(y_testとy_predで一致しているもの)を総数で割ることで表すことができます。
correct = len(results_test.loc[results_test["y_test"]==results_test["y_pred"]])results_testのカラムy_testとresults_testのカラムy_predの値が一致しているものをcorrectに格納します。
data_count = len(results_test)results_testの総数をdata_countに格納します。
score_test = correct / data_count正解数を総数で割ることで出た正解率をscore_testに格納します。

正解率はおおよそ89%と出ました。
学習データで予測した精度と評価用データで予想した精度の差が小さい方がいいのですが、
ここで精度を算出してみます。
print(model.score(X_test,y_test))
print(model.score(X_train,y_train))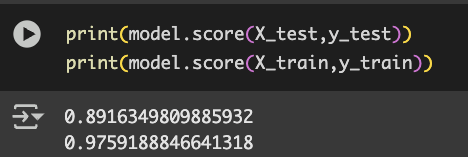
学習用データが89%で評価用データが97%という結果になりました。
ここで今回の結果に影響している変数を確認してみます。
以下のコードで、を実行します。
importance = pd.DataFrame({"feature_names":X.columns, "coefficient":model.feature_importances_})
importance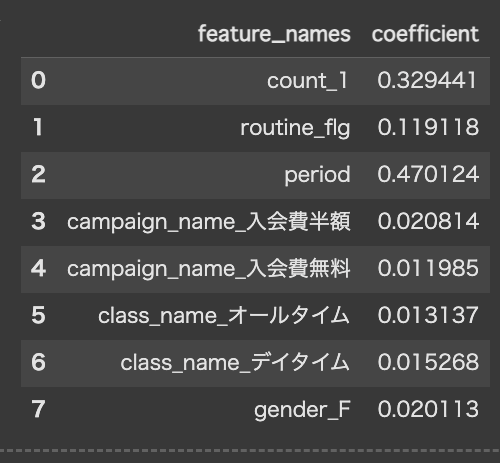
period(在籍期間)が最も高い数値を出していて、今回の結果に最も影響を及ぼしたことがわかります。
まとめ
今回はカテゴリカル変数を持ちいたカテゴリー変数化や決定木を用いて顧客の継続/退会を予測を行いました。
1つ1つのコードの意味を確かめながら、予測のやり方や仕組みを理解できました。
精度は評価用データが97%と過学習傾向傾向になっていたので、もっと理想的なモデルを作成できるようになりたいです。
ありがとうございました!

コメント