
こんばんは、Yuinaです🍵
本日は、前回の続きでデータ分析100本ノックの5章43本目から進めていきます。
よろしくお願いいたします!
ノック43本目:継続顧客データ作成しよう
42本目のノックでは退会データを作成したので、今度は継続顧客データを作成します。
conti_customer = customer.loc[customer["is_deleted"]==0]is_deleted == 0 → 退会していない顧客を抽出して conti_customer に保存します。
conti_uselog = pd.merge(uselog, conti_customer, on=["customer_id"], how="left")uselog(全ユーザーの利用履歴)と、退会していない顧客情報を customer_id で結合します。
conti_uselogの状態を確認します。
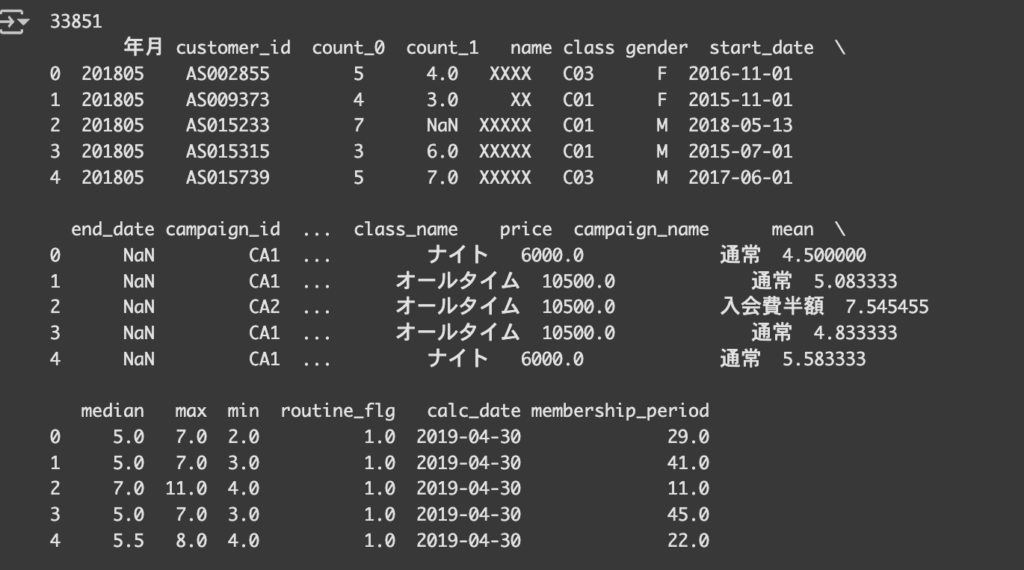
conti_uselog = conti_uselog.dropna(subset=["name"])顧客が継続していれば各カラムの中に情報が付きますが、 NaN になっている(=退会済み)でconti_customer(=継続顧客)にいない人のログを削除して、継続顧客だけを残します。(退会している人には name などが NaN になります。)
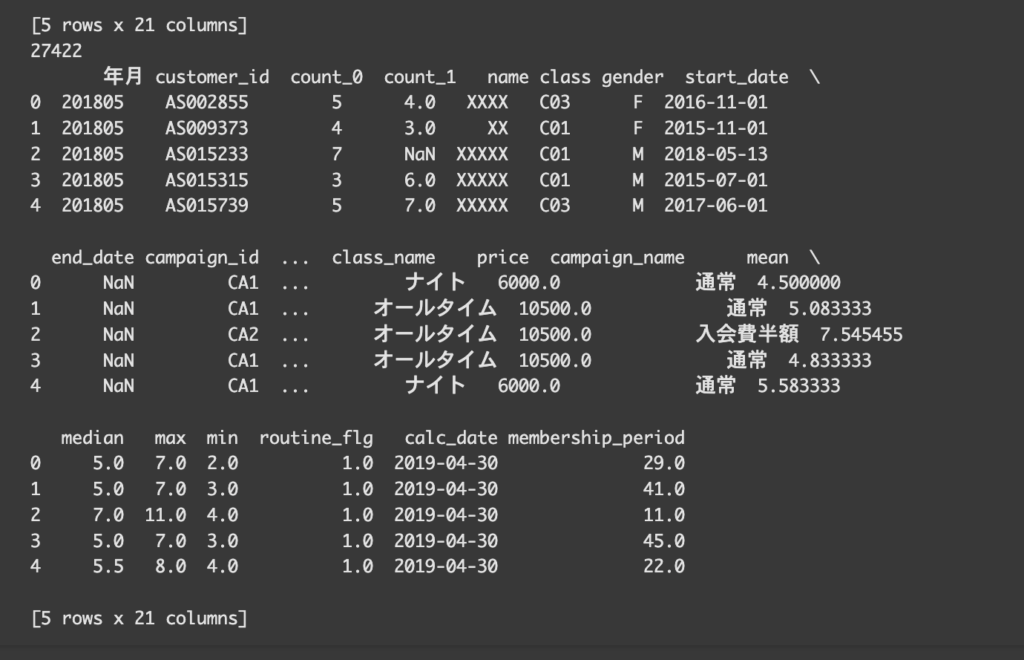
再度conti_uselogを確認してみると、データの件数が減ったことがわかります。
ログが削除されたことが確認できました。
print(conti_uselog["name"].isna().sum())心配なので、上記のコードで欠損値の有無を確認します。
退会データが1104件で継続顧客のデータが27422件不均衡なデータになってしまうため、
サンプル数を調整していく必要があります。
ここからは、conti_uselog(継続顧客の利用ログ)から 「一人につき1件だけ」をランダムに抽出してる処理を行います。
conti_uselog = conti_uselog.sample(frac=1, random_state=0).reset_index(drop=True)sample(frac=1) はデータをシャッフルし、
random_state=0 を指定することで、毎回同じシャッフル結果になります(再現性あり)
なおsample(frac=1, random_state=42)と書くと、データをランダムにシャッフルするけど毎回同じ順番になります(再現可能)
今回は、0でも42でも999でもなんでもいいみたいです。
reset_index(drop=True) は、インデックスを振り直しています。
conti_uselog = conti_uselog.drop_duplicates(subset="customer_id")customer_id ごとに 重複を削除しています。
ノック44本目:予測する月の在籍期間を作成する
predict_data["period"] = 0
predict_data["now_date"] = pd.to_datetime(predict_data["年月"], format="%Y%m")predict_dataにperiodという列を作って初期化しています。
「年月」列を datetime 型に変換し、「今の年月」として扱えるようにしています。
predict_data[“start_date”] = pd.to_datetime(predict_data[“start_date”])
入会日もdatetime型に変換し、now_dateと揃えています。
for i in range(len(predict_data)):
delta = relativedelta(predict_data.loc[i, "now_date"], predict_data.loc[i, "start_date"])
predict_data.loc[i, "period"] = int(delta.years*12 + delta.months)
relativedelta を使って「今の年月」と「入会日」の差を取ります。
「年 * 12 + 月」で、在籍月数に変換します。
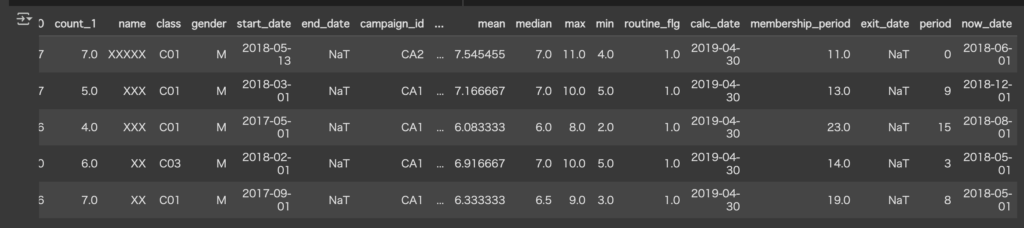
periodに在籍月数が表示されました。
predict_data.isna().sum()で欠損値を確認します。
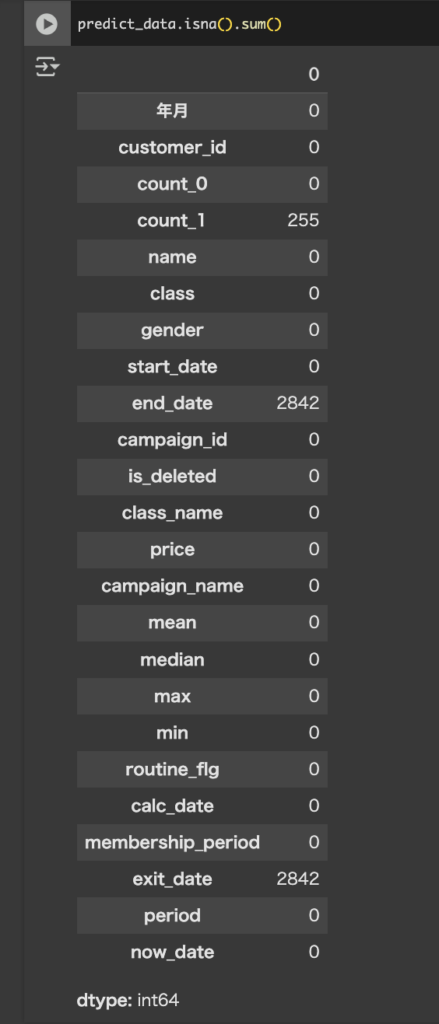
count_1に255件ありました。(end_dateとexit_dateは、ジム契約継続中の顧客の退会履歴がNULLになっているだけなのでそのままで大丈夫です)
count_1が欠損している(=前月にログがなかった)データだけ除外します。
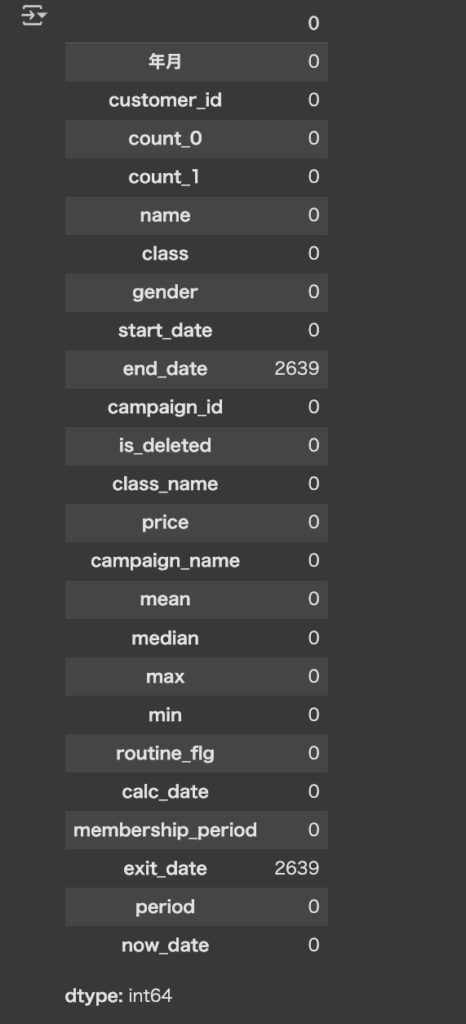
end_dateとexit_dateにも欠損値があったみたいです。
まとめ
本日はノック43,44,45本目の解説を行いました。
重複しているデータや欠損値などは頻繁に確認するのが大切だと思いました。
ありがとうございました!

コメント