
こんにちは、Yuinaです🥐
昨日は、検索した市区町村名を地図に表示するWebアプリを作ってみました。
その中で、PythonのpandasとMySQLの相性が抜群!という発見があり、
「もっとデータで遊んでみたいな」と思うようになりました。
実は、データベースの学習を始める前に、少しだけ機械学習の練習問題に取り組んでいたこともあり、
今回はその流れを活かして、MySQLとPythonを組み合わせて住所データのクラスタリングに挑戦してみます。
緯度・経度の情報をもとに、都市部がどのあたりなのかを分析してみたいと思います!
🔧 今回の環境はこちら
- Python 3.12(ローカル/VSCode)
- MySQL(Ubuntu)
- macOS(M3)
前提:ブラウザ上で latest.csv をダウンロード済み(※前回の投稿をご参照ください)
よろしくお願いいたします!
テーブルを作ろう
まず、DBの中にテーブルを作って、ファイルの中身を格納します。
post_office_geo_sampleというテーブル名にしました。
CREATE TABLE post_office_geo_sample(
id INT AUTO_INCREMENT PRIMARY KEY,
pref_name VARCHAR(100),
city_name VARCHAR(100),
town_name VARCHAR(100),
lat DECIMAL(10,7),
lng DECIMAL(10,7),
UNIQUE (pref_name, city_name, town_name, lat, lng)
);データをインポートします。
latest_dataテーブルは、latest.csvのデータの中身が全部入っているテーブルです。
今回は、latest_dataテーブルの都道府県名、市区名、町村名、緯度、経度(カラム名:pref_name, city_name, town_name, lat, lng)のデータを入れていきます。
INSERT IGNORE INTO post_office_geo_sample (pref_name, city_name, town_name, lat, lng)
SELECT pref_name, city_name, town_name, lat, lng
FROM latest_data;データが正しく挿入されたか確認します。
SELECT * FROM post_office_geo_sample LIMIT 100;テーブルはこんな感じになります。
続いて、緯度・経度の欠損値の確認をします。
SELECT
SUM(lat IS NULL) AS null_lat_count,
SUM(lng IS NULL) AS null_lng_count
FROM post_office_geo_sample;
441件の欠損値が見つかりました。
平均値で補完するか削除するかで迷いましたが、
都市部をクラスタリングで出すなら、
位置情報が揃ってるデータのみに絞ることにします。
以下のクエリ文を実行して、欠損値を削除します。
DELETE FROM post_office_geo_sample
WHERE lat IS NULL OR lng IS NULL;再び、欠損値の有無を確認します。
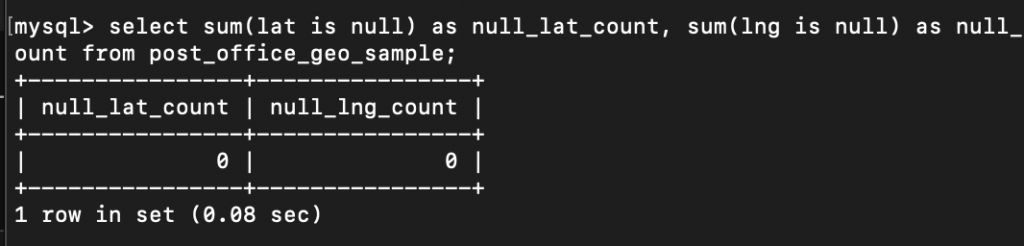
緯度・経度のデータの欠損値は無くなりました。
プログラムを作成してみよう
今回は、pandas,sqlalchemy,sklearn,matplotlib,foliumのライブラリを使いました。
PythonとMySQLとの接続はSQLAlchemyを使いました。
前回まではカーソルを使っていましたが、
今回は、データ抽出・分析向きであるSQLAlchemyを使います。
以下に、それぞれの特性をまとめています。
| 比較項目 | SQLAlchemy | Cursor |
|---|---|---|
| 主な用途 | データフレーム操作に便利(pandasと相性◎) | 細かいSQL操作に便利(標準的なDB操作) |
| 接続方法 | 抽象化されていてシンプル | 明示的に接続・カーソル作成が必要 |
| 利点 | pd.read_sql()でそのまま読み込める | トランザクションやエラーハンドリングの制御がしやすい |
| 向いてる処理 | データの抽出・分析 | データの更新・挿入・削除 |
そして、実際に作成したプログラムがこちらになります。
# 必要なライブラリ
import pandas as pd
from sqlalchemy import create_engine
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
import folium
user = "***"
password = "***"
host = "***"
database = "***"
port = "***"
# SQLAlchemyでMySQLに接続
engine = create_engine(f"mysql+pymysql://{user}:{password}@{host}:{port}/{database}")
# データの読み込み
query = "SELECT * FROM post_office_geo_sample"
df = pd.read_sql(query, engine)
# 緯度経度でクラスタリング(ここでは3クラスタにグループ分けしている)
coords = df[['lat', 'lng']]
kmeans = KMeans(n_clusters=3, random_state=42)
df['cluster'] = kmeans.fit_predict(coords)
# matplotlibで散布図として可視化
centers = kmeans.cluster_centers_
plt.figure(figsize=(8, 6))
for i in range(3):
clustered = df[df['cluster'] == i]
plt.scatter(clustered['lng'], clustered['lat'], label=f"class{i}")
plt.scatter(centers[:,1], centers[:,0], c='black', marker='x', s=200, label='center')
plt.title("Where is center city?")
plt.xlabel("lon")
plt.ylabel("lat")
plt.legend()
plt.grid(True)
plt.tight_layout()
plt.show()
# foliumで地図を可視化
map_center = [df['lat'].mean(), df['lng'].mean()]
m = folium.Map(location=map_center, zoom_start=12)
colors = ['red', 'yellow', 'green', 'blue', 'orange', 'purple']
for _, row in df.iterrows():
folium.CircleMarker(
location=[row['lat'], row['lng']],
radius=5,
color=colors[row['cluster'] % len(colors)],
fill=True,
fill_opacity=0.7,
popup=f"{row['pref_name']} {row['city_name']} {row['town_name']}"
).add_to(m)
# 地図を保存
m.save("post_office_clusters_map.html")クラスタリングの部分を解説します。
KMeans(n_clusters=3, random_state=42) は、データを「3つのクラスタに分ける」クラスタリングモデルを作成しています。
fit_predict(coords) は、クラスタリングモデルのデータを学習(クラスタ中心点の決定)し、各データ点が属するクラスタを予測しています。
得られたクラスタ番号を DataFrame の cluster (カラム名)に格納しています。
イメージはこんな感じです。
| lat | lng | cluster |
| 35.6 | 139.7 | 0 |
| 43.0 | 141.3 | 2 |
| 34.7 | 135.5 | 1 |
| ・・・ | ・・・ | ・・・ |
このようにすることで、後からクラスタごとの可視化や分析ができるようになります。
 | 価格:12000円 |
実行結果を確認してみよう
さて、実行結果はこのようになりました。
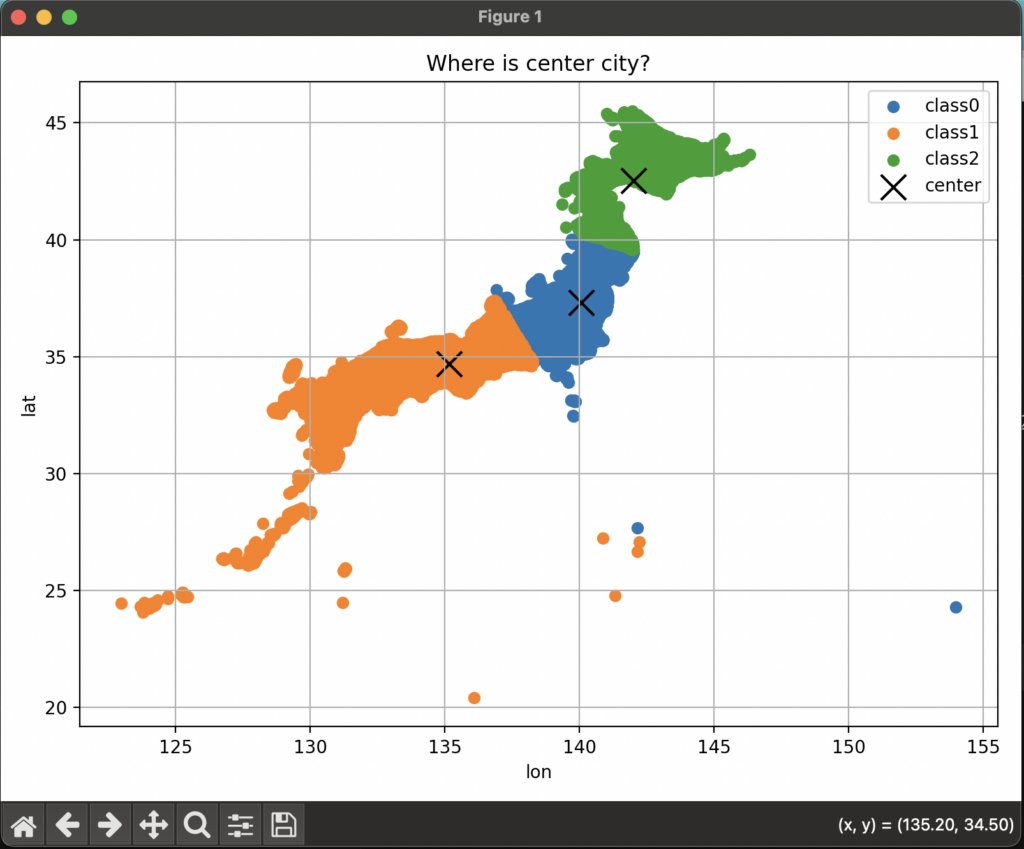
沖縄〜関西、中部〜関東、東北〜北海道というように地理的な塊でクラスタリングされているように見えます。(四国がない><)
右下には選択した場所の緯度と経度がでていますね。(x座標が経度でy座標が緯度なのちょっと違和感)
一番南側のバッテン(都市部)と出ている箇所です。
実際はどのあたりに当たるのでしょうか。
以下のクエリ文を実行して、確認してみましょう。
SELECT * FROM post_office_geo_sample WHERE lat LIKE '34.5%' AND lng LIKE '135%' limit 10;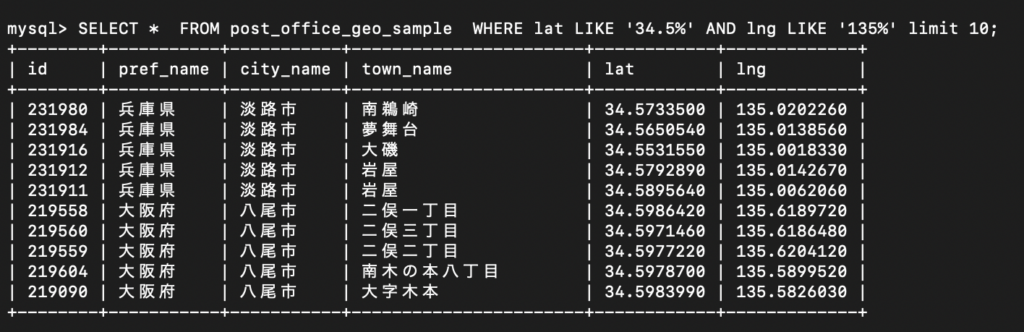
うーん。大阪府の北区、中央区、西区あたりが出てきてくれたらなと思っていたので
もう少し改善の余地ありです。
まとめ
今日は、全国の緯度・経度データを使ってクラスタリングに挑戦してみました。
今回の結果を踏まえて、データ分析の精度を上げるにはどうしたら良いのかこれから検討していきます。
それと、今後は他の分析方法も活用して、いろいろな表現ができるようになりたいです。
ありがとうございました!


コメント