
こんにちは、Yuinaです✨
前回は「Pythonデータ分析100本ノック」の第5章、決定木を使った未来予測について解説しました。
今回はその応用として、決定木を活用し、体調が悪くなるサインを予測してみたいと思います。
使用する環境は以下の通りです。
- 実行環境:Google Colab
- OS:Mac
- 言語:Python 3.12
どうぞよろしくお願いします!
ライブラリの紹介
はじめに今回使用するライブラリを紹介します。
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
train_test_splitはデータセットをトレーニングセットとテストセットに分けるための関数です。
DecisionTreeClassifierは決定木モデルを作成するためのクラスです。
accuracy_scoreはモデルの予測精度を評価するための関数です。
※accuracyの意味は精度です。
データをインポートしよう
まず、csvファイルを作成、インポートします。
今回は1週間分ではありますが、体調管理について日記をつけてみました。

ファイル名は体調予測データ.csvとします。
早速GoogleColab上でデータを読み込んでいます。
file_path = '(path)/体調予測データ.csv'指定したファイルをデータフレームとして読み込みます。
pd.read_csv(file_path)今のfile_pathの状態は、こんな感じです。

データの前処理をしよう
モデルは数値データで訓練されるため、data[‘頭痛・体調不良’] の文字列(’あり’, ‘なし’)を数値に変換しています。(カテゴリー変数化)
data['頭痛・体調不良'] = data['頭痛・体調不良'].map({'あり': 1, 'なし': 0})‘あり’ は 1 に、’なし’ は 0 に変換されます。
features = ['気分', '睡眠時間', 'ストレス度', '運動 (分)', '仕事/勉強量 (h)', '気温']
X = data[features] # 特徴量
y = data['頭痛・体調不良'] # 予測したいターゲット変数features というリストに予測に使いたい特徴量(変数)を指定しています。
気分, 睡眠時間, ストレス度, 運動 (分), 仕事/勉強量 (h), 気温の6つの特徴量を使っています。
X = data[features] は、これらの特徴量の列をデータフレームから抽出して、Xに格納します。
y = data[‘頭痛・体調不良’] は、予測したいターゲット(出力データ)である 「頭痛・体調不良」を指定しています。
def time_to_minutes(t): h, m = map(int, t.split(":")) return h * 60 + m
data['起床時間'] = data['起床時間'].apply(time_to_minutes)
print("=== '頭痛・体調不良'・'起床時間' を変換後のデータ ===") print(data[['頭痛・体調不良', '起床時間']].head(), "\n")ここでは起床時間を予測に使える形に変換します。
(例)7:30→450分
データを分割しよう(70% 学習用、30% テスト用)
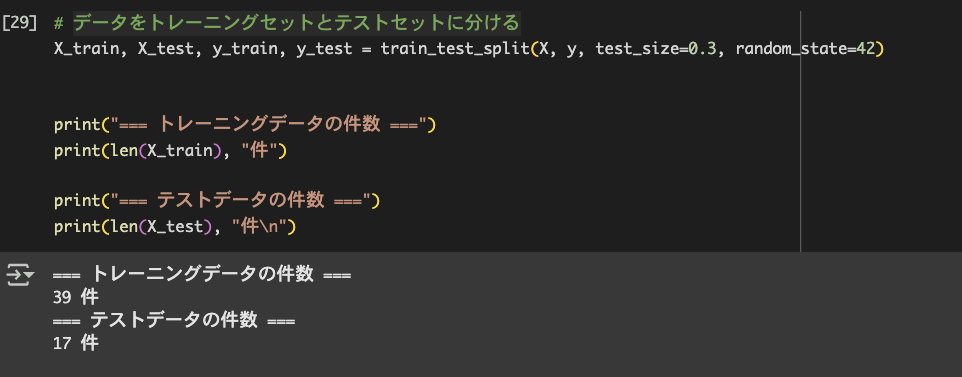
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)train_test_split は、データをトレーニングセット(モデルを学習させるためのデータ)とテストセット(モデルの精度を評価するためのデータ)に分割します。
test_size=0.3 で、全体の30%をテストデータ、残り70%をトレーニングデータとして使用することを指定しています。
random_state=42 は乱数のシード値を指定しており、これによって同じデータ分割を再現できるようにしています。
決定木モデルの作成と学習をしよう
決定木モデルを作成します。
model = DecisionTreeClassifier(random_state=42)DecisionTreeClassifierは決定木の分類モデルを作成します。
random_state=42 は、決定木を作る際のランダム性を再現するために指定しています。
続いて、モデルの学習を行います。
model.fit(X_train, y_train)model.fit(X_train, y_train) で、トレーニングデータ(X_train)とその正解ラベル(y_train)を使ってモデルを学習させています。
y_pred = model.predict(X_test)model.predict(X_test)は学習した決定木モデルを使って、テストデータ(X_test)に対する予測を行っています。
予測結果(予測された ‘頭痛・体調不良’ のラベル)が y_pred に格納されます。
予測結果は3件のみになっています。この理由は、、、
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)このとき、もし全体のデータ数が7件(たとえば4/17〜4/23の1週間分)だったら:
トレーニングデータ:約70% → 4件
テストデータ(test_size=0.3):約30% → 3件
なので、y_pred の中身も 3 件になります!
予測の精度を確認しよう
予測の学習ができたので、次は精度を確認します。
accuracy = accuracy_score(y_test, y_pred)accuracy_score(y_test, y_pred) は、テストデータの実際のラベル(y_test)と、
モデルが予測したラベル(y_pred)を比較して、予測精度を計算します。
print(f'予測精度: {accuracy * 100:.2f}%')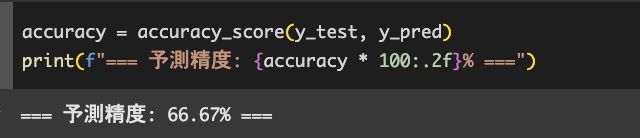
予測精度の結果は66.67%となりました。
予測結果を活用しよう
予測結果の活用についてですが、下記のコードで影響度ランキングも作ることができます。
# 特徴量の重要度を取得
importances = model.feature_importances_
importance_df = pd.DataFrame({
'特徴量': features,
'重要度': importances
}).sort_values(by='重要度', ascending=False)
print("\\n=== 特徴量の影響度ランキング(重要度順) ===")
print(importance_df)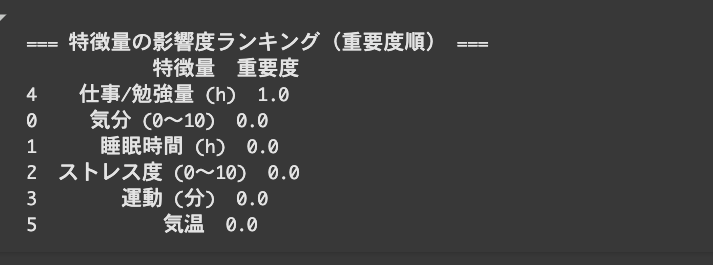
仕事/勉強量(h)の重要度が100.0%で、他は0.0%になっています。
データが少なすぎるのでしょうか。
csvファイルのデータを7件から55件に増やして、再度学習させてみました。
数値は適当に入れています。
結果、このようになりました。
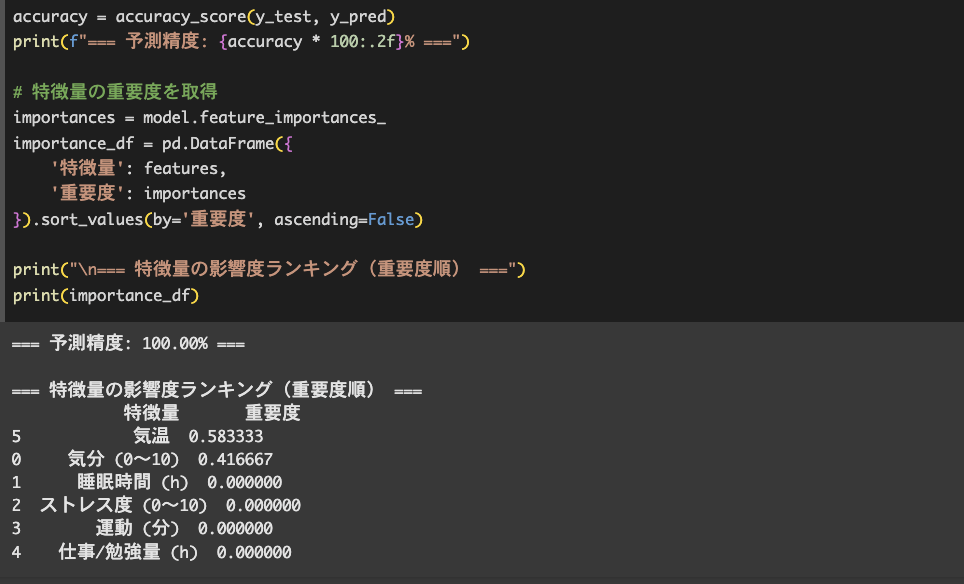
予測精度は100.00%となり、影響度ランキングは、1位は気温と2位は気分となりました。
気温と気分が、体調不良に1番影響を与えているように見えますね。
予測精度ですが、過学習の可能性があるので確認していきます。
過学習かどうか確認してみよう
訓練データとテストデータの両方が100%だったらデータがかなりシンプルで分かりやすい可能性があります。
「訓練だけ高くてテストが低い」なら過学習を疑って対策していきます。
train_acc = model.score(X_train, y_train)
test_acc = model.score(X_test, y_test)
print(f"訓練精度: {train_acc * 100:.2f}%")
print(f"テスト精度: {test_acc * 100:.2f}%")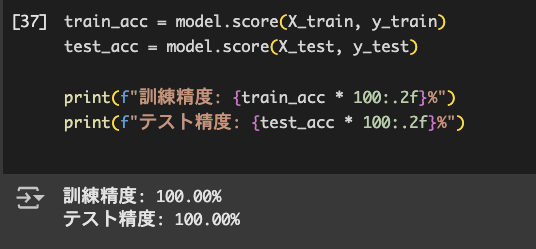
どちらも100.00%で、過学習ではない可能性が高くなってきました。
他の方法でも確かめてみます。
目的変数の分布を見てみましょう。
print("目的変数の分布(頭痛・体調不良):")
print(y.value_counts())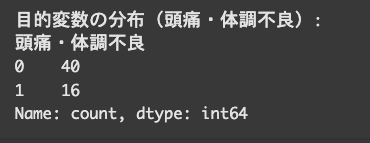
そんなに極端に偏ってるわけではないですが、少しバランスが崩れてる感じですね。
続いては、混同行列を確認して、「どれだけ正しく あり/なし を予測できてるか」を見ていきます。
from sklearn.metrics import confusion_matrix
cm = confusion_matrix(y_test, y_pred)
print("=== 混同行列 ===")
print(cm)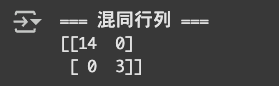
[[14 0] ← 実際「なし」→ 14件すべて正解
[[0 3]] ← 実際「あり」→ 3件すべて正解
→ 偏りに引っ張られてないし、モデルがバランスよく学習できてることがわかります✨
最後に、分類レポートで 「precision / recall / F1-score」を確認します。
それぞれの意味ですが、Precisionは「予測が正しい率」
Recallは「本物をどれだけ見逃さず拾えたか」
F1-scoreは「PrecisionとRecall のバランスをとった指標」となっております。
from sklearn.metrics import classification_report
print("=== 分類レポート ===")
print(classification_report(y_test, y_pred))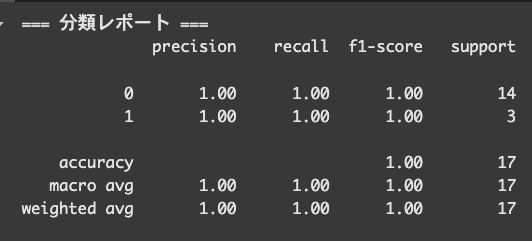
0(頭痛なし)は14件,1(頭痛あり)は3件で頭痛の有無を正確に判断しています。
分類レポートの結果から、モデルが全件を正しく予測できている可能性が高いことがわかります。
しかし、テスト件数が17件と少ないので、偶然100%だった可能性もあるので、
もう少しデータを増やして学習させてみるのもいいかもしれません。
まとめ
今回は、決定木を活用して体調予測しました。
データが少なすぎると学習がうまくいかないことがわかりました。
また、ファイル中のコメントのデータがうまく活用できなかったので、
使えるように工夫してみます。
ありがとうございました!

コメント