
こんにちは、Yuinaです🍋
今日はとても過ごしやすいお天気だったので、
すみれ系の味噌ラーメンを食べに行ってきました。
生姜がしっかり効いたスープで、とても美味しかったです!
さて、これまでの作業では、
データベースの正規化や、郵便番号から都道府県名を表示・逆引きする処理を進めてきました。
今回は、それらに加えて「データベースと地図を連携させたWebアプリ」を作っていこうと思います。
開発環境は以下の通りです:
- Python 3.12(macOS)
- MySQL(Ubuntu上)
- OS:Mac(M3チップ)
前提条件として:
pandasとStreamlitパッケージがインストール済み- Ubuntu環境とのSSH連携が完了している
それでは、よろしくお願いします!
ファイルをダウンロードしよう
今回は、こちらのオープンデータを使わせていただきました。
ターミナルにて、ダウンロードしていきます。
ダウンロードコマンド:
wget https://geolonia.github.io/japanese-addresses/latest.csv -O /
/(yourPath)/latest.csvテーブルを作って、インポートしよう
先ほどダウンロードしたデータを入れるテーブルを作ります。
CREATE TABLE latest_data (
pref_code VARCHAR(5), -- 都道府県コード
pref_name VARCHAR(50), -- 都道府県名
pref_kana VARCHAR(50), -- 都道府県名カナ
pref_romaji VARCHAR(50), -- 都道府県名ローマ字
city_code VARCHAR(10), -- 市区町村コード
city_name VARCHAR(100), -- 市区町村名
city_kana VARCHAR(100), -- 市区町村名カナ
city_romaji VARCHAR(100), -- 市区町村名ローマ字
town_name VARCHAR(100), -- 大字町丁目名
town_kana VARCHAR(100), -- 大字町丁目名カナ
town_romaji VARCHAR(100), -- 大字町丁目名ローマ字
street_alias VARCHAR(100), -- 小字・通称名
lat DECIMAL(10,6), -- 緯度
lng DECIMAL(10,6) -- 経度
);データをインポートしていきます。
LOAD DATA INFILE '/var/lib/mysql-files/latest.csv'
INTO TABLE latest_data
CHARACTER SET utf8mb4
FIELDS TERMINATED BY ','
ENCLOSED BY '"'
LINES TERMINATED BY '\n'
IGNORE 1 ROWS
(@pref_code, @pref_name, @pref_kana, @pref_romaji, @city_code, @city_name, @city_kana, @city_romaji, @town_name, @town_kana, @town_romaji, @street_alias, @lat, @lng)
SET
pref_code = NULLIF(@pref_code, ''),
pref_name = NULLIF(@pref_name, ''),
pref_kana = NULLIF(@pref_kana, ''),
pref_romaji = NULLIF(@pref_romaji, ''),
city_code = NULLIF(@city_code, ''),
city_name = NULLIF(@city_name, ''),
city_kana = NULLIF(@city_kana, ''),
city_romaji = NULLIF(@city_romaji, ''),
town_name = NULLIF(@town_name, ''),
town_kana = NULLIF(@town_kana, ''),
town_romaji = NULLIF(@town_romaji, ''),
street_alias = NULLIF(@street_alias, ''),
lat = NULLIF(@lat, ''),
lng = NULLIF(@lng, '');最初、lat(緯度)・lon(経度)に空文字(“)が含まれていたので、MySQLのdecimal(10,6) 型は空文字をそのまま入れられないでした。
NULLIF(@lat, ”) により空文字が NULL に変換され、decimal型のデータも挿入できるようにしました。
こちらでインポートしたデータの件数を確認できます。
-- 欠損している緯度・経度の件数
SELECT COUNT(*) FROM latest_data WHERE lat IS NULL OR lng IS NULL;
-- 都道府県ごとの件数を確認
SELECT pref_name, COUNT(*) FROM latest_data GROUP BY pref_name ORDER BY COUNT(*) DESC;正規化しよう
csvファイルのデータがインポートできたので、次はテーブルを都道府県、市区、町村、緯度経度別に分割して正規化していきます。
まずは、都道府県テーブルを作ります。
(なぜ、テーブル名をprefectures2にするかというと、
すでにprefecturesという名前のテーブルを作成しているためです。)
都道府県テーブル:
mysql> CREATE TABLE prefectures2(
-> pref_code VARCHAR(5) PRIMARY KEY,
-> pref_name VARCHAR(50),
-> pref_kana VARCHAR(50),
-> pref_romaji VARCHAR(50)
-> );データをインポートします。
ysql>
mysql> INSERT INTO prefectures2
-> SELECT DISTINCT pref_code, pref_name, pref_kana, pref_romaji
-> FROM latest_data
-> WHERE pref_code IS NOT NULL;市区テーブル:
mysql> CREATE TABLE cities2 (
-> city_code VARCHAR(10) PRIMARY KEY,
-> city_name VARCHAR(100),
-> city_kana VARCHAR(100),
-> city_romaji VARCHAR(100),
-> pref_code VARCHAR(5),
-> FOREIGN KEY (pref_code) REFERENCES prefectures2(pref_code)
-> );データをインポートします。
mysql> INSERT INTO cities2
-> SELECT DISTINCT city_code, city_name, city_kana, city_romaji, pref_code
-> FROM latest_data
-> WHERE city_code IS NOT NULL;町村テーブル:
CREATE TABLE areas2(
-> id INT AUTO_INCREMENT PRIMARY KEY,
-> town_name VARCHAR(100),
-> town_kana VARCHAR(100),
-> town_romaji VARCHAR(100),
-> street_alias VARCHAR(100),
-> city_code VARCHAR(10),
-> FOREIGN KEY (city_code) REFERENCES cities2(city_code)
-> );データをインポートします。
INSERT INTO towns2(town_name, town_kana, town_romaji, street_alias, city_code)
-> SELECT DISTINCT town_name, town_kana, town_romaji, street_alias, city_code
-> FROM latest_data
-> WHERE town_name IS NOT NULL;緯度・経度テーブル:
CREATE TABLE geo_locations (
-> id INT AUTO_INCREMENT PRIMARY KEY,
-> town_id INT,
-> lat DECIMAL(10,6),
-> lng DECIMAL(10,6),
-> FOREIGN KEY (town_id) REFERENCES towns2(id)
-> );データをインポートします。
NSERT INTO geo_locations (town_id, lat, lng)
-> SELECT t.id, d.lat, d.lng
-> FROM latest_data d
-> JOIN towns2 t
-> ON d.town_name = t.town_name AND d.city_code = t.city_code
-> WHERE d.lat IS NOT NULL AND d.lng IS NOT NULL;テーブルを結合しよう
テーブルを扱いやすい形に結合します。
SELECT
pref.pref_name,
city.city_name,
a.town_name,
geo.lat,
geo.lng
FROM areas2 a
JOIN geo_locations geo ON a.id = geo.town_id
JOIN cities2 city ON a.city_code = city.city_code
JOIN prefectures2 pref ON city.pref_code = pref.pref_code
WHERE geo.lat IS NOT NULL AND geo.lng IS NOT NULL
LIMIT 100;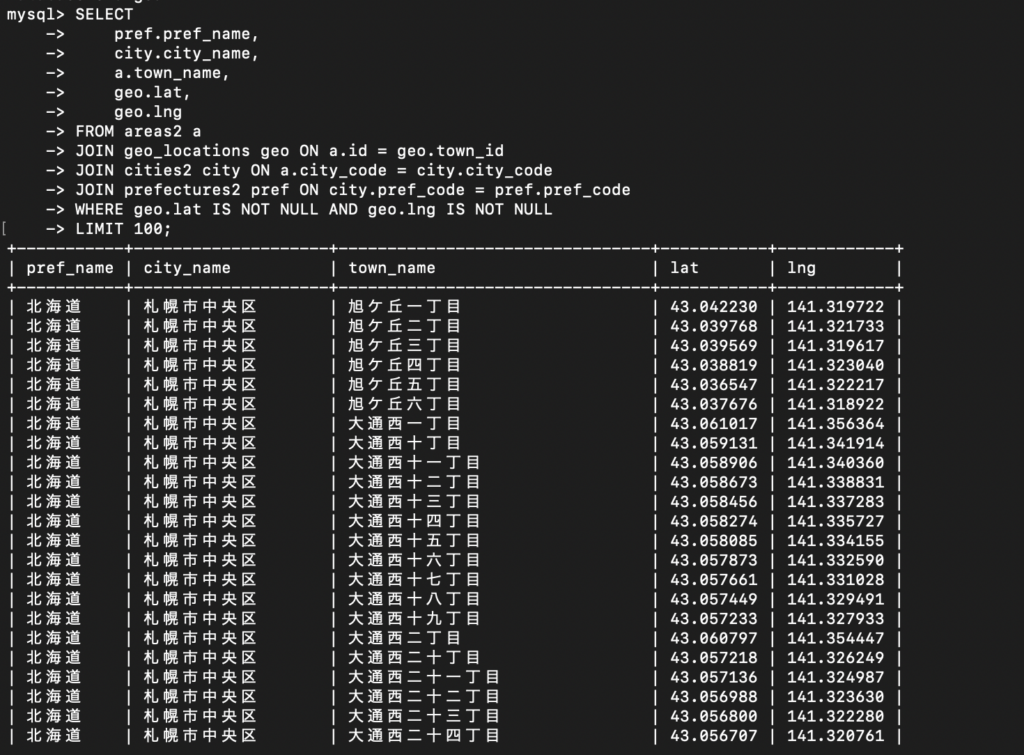
プログラムを書いてみよう
今回使用したプログラムはこちらになります。
streamlitというパッケージを使ってブラウザ上で地図を表示させます。
import streamlit as st
import pandas as pd
import mysql.connector
# MySQLデータベースに接続
conn = mysql.connector.connect(
host='***', # IPアドレス
user='***', # ユーザー名
password='***', # パスワード
database='***', # データベース名
connection_timeout=5,
charset='utf8mb4'
)
# 市区町村名の検索を受け付ける
search_term = st.text_input("市区町村名を入力してください:")
# データベースから市区町村を検索
if search_term:
query = f"""
SELECT
pref.pref_name,
city.city_name,
a.town_name,
geo.lat,
geo.lng
FROM areas2 a
JOIN geo_locations geo ON a.id = geo.town_id
JOIN cities2 city ON a.city_code = city.city_code
JOIN prefectures2 pref ON city.pref_code = pref.pref_code
WHERE geo.lat IS NOT NULL AND geo.lng IS NOT NULL
AND (city.city_name LIKE '%{search_term}%' OR a.town_name LIKE '%{search_term}%')
LIMIT 100;
"""
df = pd.read_sql(query, conn)
# 地図に検索した結果を表示
if not df.empty:
st.map(df[['lat', 'lng']])
else:
st.write("該当する市区町村が見つかりませんでした。")
# データベース接続を閉じる
conn.close()実行したところ、[streamlit.errors.StreamlitAPIException: Map data must contain a longitude column named: ‘LON’, ‘LONGITUDE’, ‘lon’, ‘longitude’. Existing columns: ‘lat’, ‘lng’]のようなエラーが出てきました。
Streamlitの地図表示には、longitudeというカラム名が必要ですが、dfのデータフレームにはそのカラムがlngという名前で存在していることが原因みたいです。
df内のlngカラムの名前をlongitudeに変更したものがこちらです↓
import streamlit as st
import pandas as pd
import mysql.connector
# MySQLデータベースに接続
conn = mysql.connector.connect(
host='***', # IPアドレス
user='***', # ユーザー名
password='***', # パスワード
database='***', # データベース名
connection_timeout=5,
charset='utf8mb4'
)
# 市区町村名の検索を受け付ける
search_term = st.text_input("市区町村名を入力してください:")
# データベースから市区町村を検索
if search_term:
query = f"""
SELECT
pref.pref_name,
city.city_name,
a.town_name,
geo.lat,
geo.lng
FROM areas2 a
JOIN geo_locations geo ON a.id = geo.town_id
JOIN cities2 city ON a.city_code = city.city_code
JOIN prefectures2 pref ON city.pref_code = pref.pref_code
WHERE geo.lat IS NOT NULL AND geo.lng IS NOT NULL
AND (city.city_name LIKE '%{search_term}%' OR a.town_name LIKE '%{search_term}%')
LIMIT 100;
"""
df = pd.read_sql(query, conn)
# データフレームのカラム名を変更
if not df.empty:
df = df.rename(columns={'lat': 'latitude', 'lng': 'longitude'})
# 地図に検索した結果を表示
st.map(df[['latitude', 'longitude']])
else:
st.write("該当する市区町村が見つかりませんでした。")
# データベース接続を閉じる
conn.close()修正が必要なエラーを吐かなかったので、大丈夫だと思います。
ターミナルでrunコマンドをStreamlitを実行してみます。
streamlit run city_search_app.py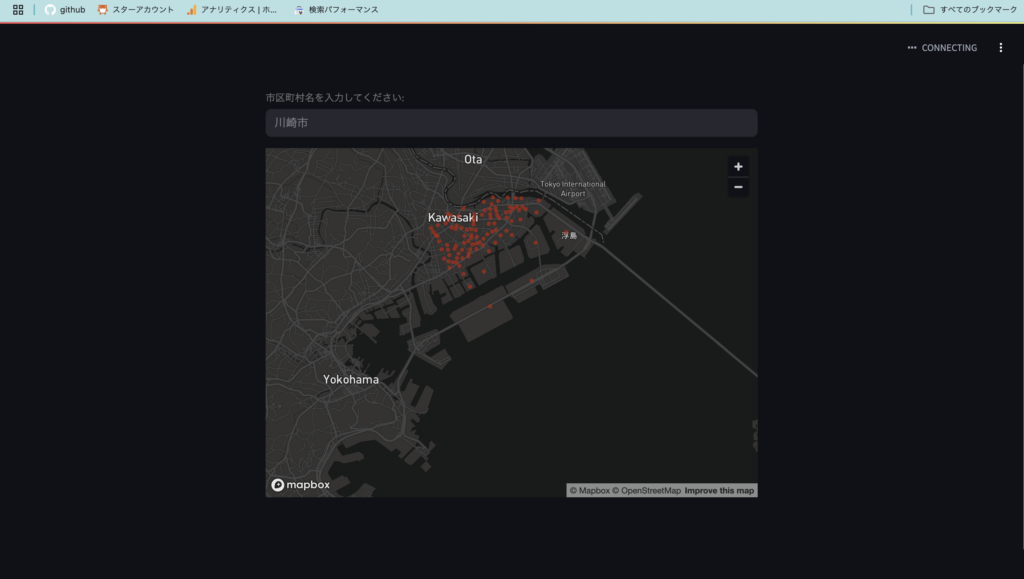
完成しました✨
まとめ
今回は、市区町村名を入力すると、該当する市区が一覧で表示されて、地図上にも位置が表示されるWebアプリをStreamlitで作りました。
MySQLを使って市区町村のデータを扱うことで、ちょっとしたデータベースの扱いにも慣れることができました。
今後はデータベースとpandasと組み合わせたデータ解析とか面白そうなので、遊んでみようと思います。
読んでくださってありがとうございました。


コメント